
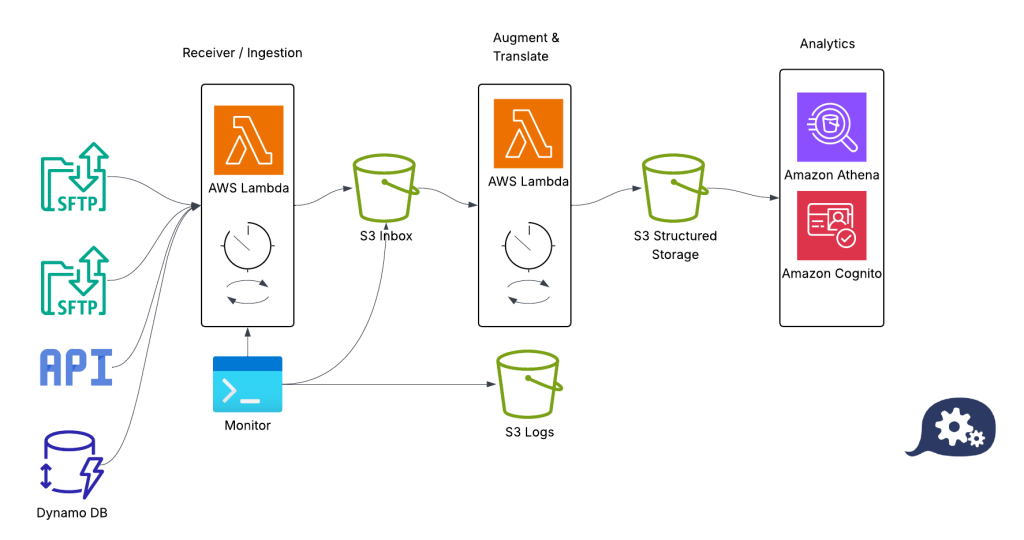
This design pattern was implemented to process, store and analyse airline flight booking information.
The sales files were received daily as HOT EDIFACT messages in a daily summary after each sales office closed.
On receipt, a script would detect the file presence on the SFTP server and copy the messages to an S3 storage bucket, removing any PII.
If the messages failed to arrive an email alert was generated by the monitoring script to alert the team.
Once stored in S3, A transform script would process the EDIFACT messages into PARQUET format and separate the EDIFACT messages into their particular distinct elements.
These were output into structured S3 folders based on the date.
Amazon Athena was used to build an analysis platform over the S3 data, allowing the revenue management team to view and analyse booking profiles in a structure query language model.
The particular design pattern was extremely cost efficient and provided robust analytics for the revenue management team.
Considerations for future re-deployment:
- If higher volume querying of the data is a possibility, then a structured database may prove more cost effective.
- Additional automatic reporting would be built based on metrics the management team would need to use to optimise load factor and revenue management.
- As shown in the diagram above, additional ingress mechanisms would be built to allow a variety of sources to feed the data pipeline, in addition to SFTP.
Pro’s & Cons:
- Great for low volume structured data
- Ideal for File based ingestion
- Infrequent querying of result sets
- Costs increase significantly with high volumes of stored data or queries across a large date range
- Not suited to unstructured data ingestion